2019-08-17 Final report.
The goal of this 2019 Google Summer of Code project is to develop a tool with which to transparently proxy applications that use the Wayland protocol to be displayed by compositors. Unlike the original X protocol, only part of the data needed to display an application is transferred over the application's connection to the compositor; instead, large information transfers are made by sharing file descriptors over the (Unix socket) connection, and updating the resources associated with the file descriptors. Converting this side channel information to something that can be sent over a single data stream is the core of this work.
The proxy program I have developed for the project is called Waypipe. It can currently be found at gitlab.freedesktop.org/mstoeckl/waypipe. (I am currently looking for a better stable path at which to place the project; the preceding URL will be updated once this is done.) A few distributions have already packaged the program; see here; alternatively, to build and run the project, follow the instructions in the README and the man page. My work is clearly identified by the commit logs, and amounts to roughly ten thousand lines of C code, and a few hundred of Python.
The following image shows the typical setup for the proxy. Two instances of the program must be run, a waypipe server on the remote system, and a waypipe client on the local system. The waypipe server pretends to be a Wayland compositor, and offers a Unix socket over which applications can connect. When they do so, a the waypipe server creates a new connection handling process, whose task it is to convert the Wayland protocol messages (and file descriptor updates) made by the application to a single data stream. The connection handler then connects to a Unix socket that is forwarded (via ssh) from a socket created by the waypipe client process. Messages to the communication channel are then decoded by another connection handler, which connects to the local Wayland compositor and pretends to be the remote application.

The individual connection handlers leave the wire format of the Wayland protocol messages mostly unchanged, prefixing collections of messages with a lightweight header. Some editing is done, for instance to strip out messages advertising capabilities that can or should not be proxied (privileged graphics card access). File descriptors provided by either the application (or the compositor), on the other hand, are replaced by messages that tell the remote Waypipe instance to create a file descriptor with matching properties, and send it on to the compositor (or the application.) Additional messages are sent to replicate any changes to the local file descriptors.

As the vast majority of file descriptor updates are changes to shared memory buffers (or DMABUFs) containing image data, I will only describe the main mechanism used to replicate changes. It is a standard technique for distributed shared memory; instead of sending the entire memory region when the Wayland protocol messages indicate that there is a change, Waypipe maintains a private copy of the each shared memory region, and only sends the data which has changed since the last time the private copy was synchronized with the shared memory region. The format used to track the changes is illustrated in the following image; it consists of a series of runs of changed data, prefixed by the range in the buffer to which the run corresponds.

Waypipe supports many quality of life features, including a user-friendly command line wrapper for ssh, hardware accelerated video encoding, transfer compression with either LZ4 or Zstd, and a method to reconnect applications when the ssh connection breaks. With more recent kernels and versions of Mesa that support DMABUFs (GPU-side buffers), it can proxy programs that render images using OpenGL.
The most difficult technical challenge with Waypipe so far has been the buffer management logic, and the way this interacts with multithreading and reconnection support. In addition to the expected overflow and race conditions bugs involved, it's been surprisingly difficult to find a simple way to satisfy all the requirements without performing extra memory copies or using dynamic memory allocation for every file descriptor update message sent over the communication channel. I've chosen to use malloc all over the place, and deal with all the error checking that involves. Due to the complexity involved (and the fact the decompression is generally faster than the network), I still don't have a multithreaded message decompression pathway.
There are a few things that I may yet implement in Waypipe over the next few months. As much of the code was written under the assumption that it would soon be rewritten, many of the error checking paths, especially those related to memory allocation failure, are incomplete or untested. There are also a few performance optimizations with the buffer change detection mechanism that I'd like to try, most notably using a fast hash function to reduce memory bandwidth consumption. It would also be nice to use the C11 atomic operations to reduce the amount of code in lock-protected critical sections, since lock holder preemption contributes to worst-case latency.
2019-08-10 As this GSOC project approaches its end, I've been testing and refactoring the code for waypipe. The only new feature of note is a waypipe bench subprogram, which makes it easier to estimate which compression settings, precisely, are appropriate for a combination of bandwidth and machine performance. The bandwidth must be specified on the command line, since real network stacks include buffering that would make online measurements very difficult. (The benchmark design implicitly assumes that decompression time on the remote machine never delays the critical path for a transfer, or at the very least, is far less significant than the compression algorithm and level settings.) The results of this program are mostly predictable. Because frames containing text tend to compress better than frames containing rendered 3d scenes or pictures, the compression level which minimizes transfer latency, at high bandwidths, is typically higher for text heavy images, since even fast compression methods offer significant space reduction. At low bandwidths, the reverse holds, since beyond a point images require enough transfer time that there is enough time for very high levels of compression.
The remaining changes are varied. I've also extended support for DMABUFs to include some older versions of Mesa whose backends don't yet support the GBM modifier code. A crash or two introduced over the last few weeks has been fixed. The headless testing script now also checks that the reconnection support added a few weeks ago works. waypipe now compiles with -Wconversion, and some unnecessary wire format padding has been removed.
2019-08-03 The result of all the diff construction testing and sample implementations ... is an unchanged diff format. In my opinion, the scenario that most needs optimization is when a small change is made to a large buffer, and detailed damage tracking is unavailable. Then the main source of delay in the program is the time needed to scan through the unchanged portion of the buffer. On the other hand, when most of the buffer has changed, the data transfer time (and any compression/decompression stages) will take enough time that a 5% increase in diff runtime will be hidden by the other operations. In essence, it's better to optimize the diff for text input than for games. Based on the target scenario, the bitset format was ruled out, because a 1/64th control data overhead is huge when only 1/1000th of the buffer changed, and the time needed to convert the bitset to another format added too much slowdown, even in the case where no data changed. The split variation on the standard diff format was also discarded, as it required a bit more complexity to manage two buffers, while not significantly improving performance.
A key optimization used by the standard diff method is "windowing": small unchanged gaps in the data stream are still copied into the diff. This speeds up diff application, by reducing the number of chunks that must be memcpy'd, as well as the number of branch mispredictions, and makes it possible to limit the number of times that the diff construction routine must switch between copying data and not copying data. The maximal size gap to be skipped is still kept relatively small, to minimize both the total diff size and the total amount of data written. (It's currently at 256 bytes, and can't go any lower than 64 bytes without breaking a key optimization for the SIMD diff routines.)
A common optimization which does not work for the diff construction methods is to run the method fully branchlessly with a single loop. While this approach is probably worth it when just constructing a diff given two buffers, waypipe's diff construction method also requires that the second buffer be updated to match the first. The fastest way to update the reference buffer, without introducing conditional code, is to mix a copy of the entire modified buffer into the diff routine. (Using masked writes to avoid actually rewriting the unchanged data is slower, due to high instruction latency.) As interleaving a data copy is still ≥ 10% slower than having a specialized loops to scan changed and unchanged data, with additional slowdown expected in conjunction with hyperthreading, the fully "branchless" approach is not worth it.
In other news, as I didn't have an AAarch64 system on hand, I upgraded a Raspberry Pi 4 from a 32-bit kernel and 32-bit userland to a 64-bit kernel and a mixture of 32-bit and 64-bit packages, with development tools consisting solely of the latter. From an existing Raspbian image, I first installed a 64-bit kernel. Converting the userland was more difficult; a versioning incompatibility between the Raspbian repositories and the Debian ones was fixed with a version renaming script. Then the armhf toolchain was uninstalled and replaced with arm64 packages, albeit for a complication with a few core packages that was resolved with dpkg --force-all and by editing the package dependency lists.
Also, reading through the Intel SDM, Vol. 3A, I found out why CPU access for the Y_TILED_CCS DMABUF modifier runs so slowly; the data appears to have been mapped as "Strong Uncacheable", so that effectively only one read or write in a thread of execution can be in progress at a time. The only ways to speed this up at the moment are to make read/write operations larger, using e.g. 32 byte (AVX) loads and stores, or to throw more hardware threads at the problem. I'm still not entirely sure why the memory for some DMABUFs is mapped as uncacheable, but then again, I've yet to read all the documentation.
2019-07-27: I've recently been working on optimizing the diff construction and application routines for waypipe, making use of SIMD instruction sets when available. So far, the speed improvement due to vectorization is small for AVX and generally negative for SSE, because the existing diff routine is already rather fast, and because determining which data has changed and then writing only that data is an inherently branchy procedure.
The following plots shows diff construction and application speeds for an initial and an final frame, using a variety of diff formats and vectorization approaches. The plots on the left correspond to a pair of frames sharing about 60% of their bytes in common; on the right, for a pair sharing about 80%. To keep this post short, I will only explain some of the formats and algorithm combinations.
memcpy (copy 64) gives the fastest results for both compression and decompression in isolation. Outside the L3, using nontemporal loads and stores (line copy stream) significantly improves performance by reducing cache traffic.memcpy, although it does win out beyond the L3 cache, presumably due to the reduced write traffic. A plain C implementation (bitset 64) is branch heavy and runs far more slowly; the SSE version currently requires too much bit manipulation code relative to the speedup that the vector registers bring. Another downside of the bitset format is that applying the resulting diff often requires many branches. The bitset run method ameliorates this by using trailing zero count intrinsics to quickly identify groups of consecutive changed blocks, but has increased overhead when changed blocks alternate with unchanged blocks.waypipe currently uses. Instead of storing a bitmap in its second data stream, the second stream is a list of intervals specified by their start and end points, which indicate the ranges of changed data. This format is faster to decompress than bitset, but at the moment the fastest construction method (split hybrid) is to create a bitset diff with AVX2 and then periodically convert added bitsets to intervals, using the contemporary tzcnt instruction to process multiple bits at a time.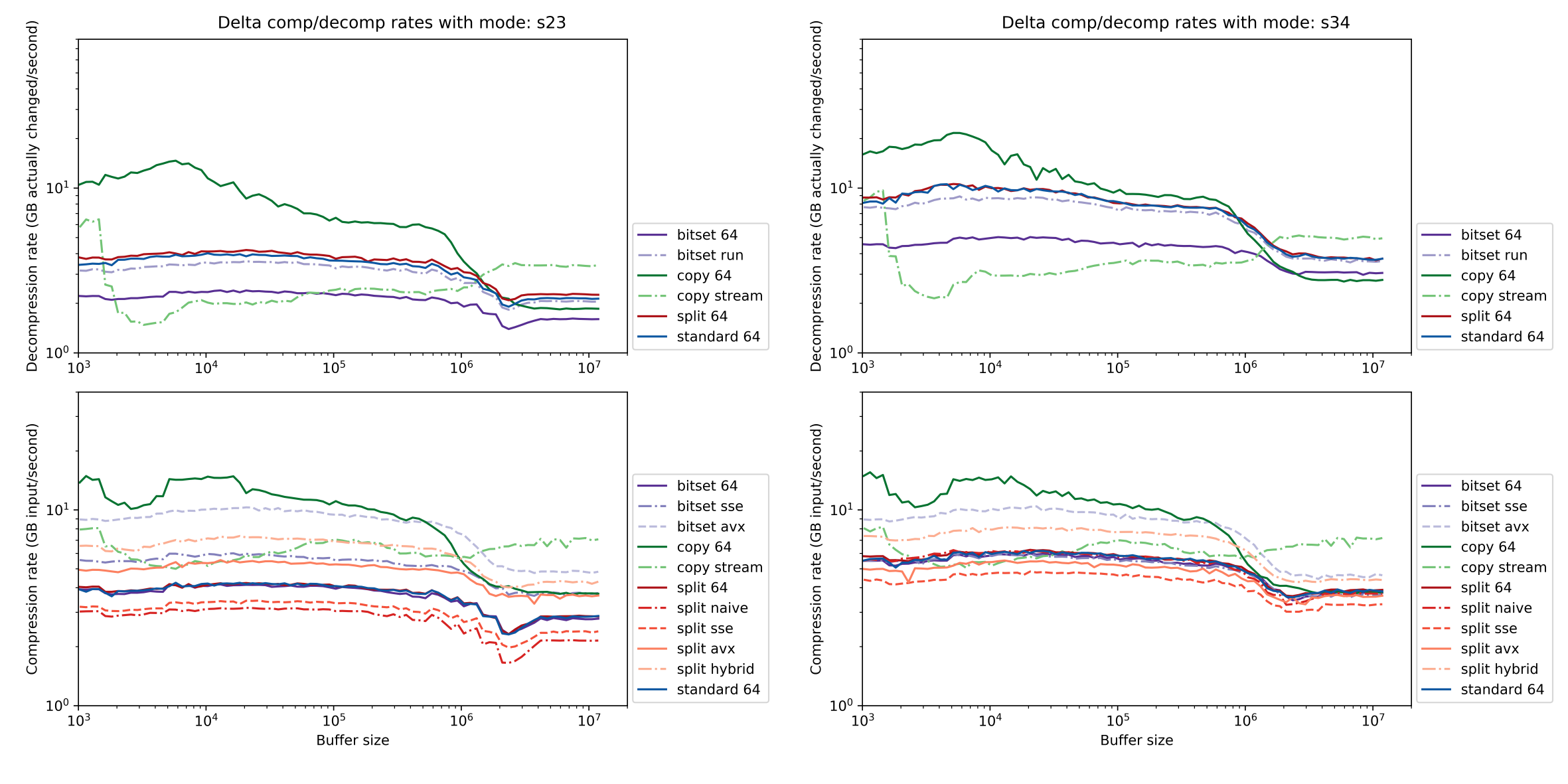
Because the diff performance depends in large part on the interaction between the patterns of changed and unchanged data in the updated diff buffer, branch prediction, cache behavior, and CPU instruction timings, the above plots should be cautiously interpreted. Furthermore, as the rate computations above were part of a standalone benchmark program, they do not take into account cache and bandwidth limitations due to multithreading or the time needed to write and read data, both of which can affect waypipe under normal use.
2019-07-18: Three large changes have been completed this week. The first is a change to the wire format used for waypipe. The previous protocol, dating back almost to the start of this project, sent a single large message containing a series of subblocks, each of which either contained Wayland protocol data, indicated that a new file descriptor was sent by the connected Wayland program, or provided all the information needed to update a given file descriptor. These file descriptor update messages used a 16-byte header containing the object id, size, type, and a very overloaded metadata field. Furthermore, the content following the header was sometimes context-dependent. For example, the first data transfer to replicate a shared memory buffer sent its initial data, while all successive messages sent a diff relative to the previous state. Because so much in the update messages was implicit, the code acquired a few unusual workarounds; for example, size extensions to a shared memory buffer were only supported by assuming the newly extended region to have contained all zeros and then sending a diff relative to that state.
The replacement wire format protocol operates with much smaller transfer units, with distinct types for the various file operations that used to be combined into a single generic header. To keep individual message sizes small, file data update operations can be split into distinct messages corresponding to different shards of a buffer. While having distinct messages for each operation does very slightly increase the bandwidth needed for a connection, it ensures that operations can be performed as soon as the corresponding message block arrives; a remote pipe or video-type DMABUF can be created before the data for its contents has fully arrived.
The second major change is the introduction of reconnection support. A common problem with proxies of any type is that when the underlying connection breaks, the remote session is not longer usable. There are workarounds, of course; screen and tmux can be run over an ssh connection to keep the remote terminal alive when the connection drops. With waypipe and Wayland applications, it's a bit more complicated, since there is state to be preserved on both sides of the connection. What waypipe now does, is implement connection resumption at the level of protocol message blocks. Both application- and display-side instances keep a queue of all the messages sent over the communication channel, only removing messages from the queue once the remote program has acknowledged that is has received them. When the connection drops, each waypipe connection handling process waits for a new connection file descriptor to be provided to it. Then the waypipe process replays all messages sent but not yet acknowledged so far, while ignoring all messages that it has already seen. Eventually the process reaches new messages, at which point waypipe proceeds as normal. (The actual implementation is slightly more complicated, optionally sending a "restart" message to ensure that the other side knows the message id of the first replayed message.)
Finally, waypipe has replaced its barrier-style multithreading implementation with a more standard queue-based thread pool. I mentioned earlier that having distinct phases for computation and writing increased transfer latency. Along with the new thread pool, buffer setup and diff operations are partitioned into small (about 256KB) chunks, with the message for a given chunks added to the outgoing transfer queue, and written to the network connection, as soon as the chunk is complete. While the time visualization method shown earlier doesn't handle overlapping time intervals very well, it suffices to show that when running a sample application with -c zstd --threads 4, the receiving waypipe instance (top row) starts to read (orange), decompress (gray), and apply (blue) buffer diffs from the connection before the other side has finished producing (purple), compressing (red), and writing (green) them.
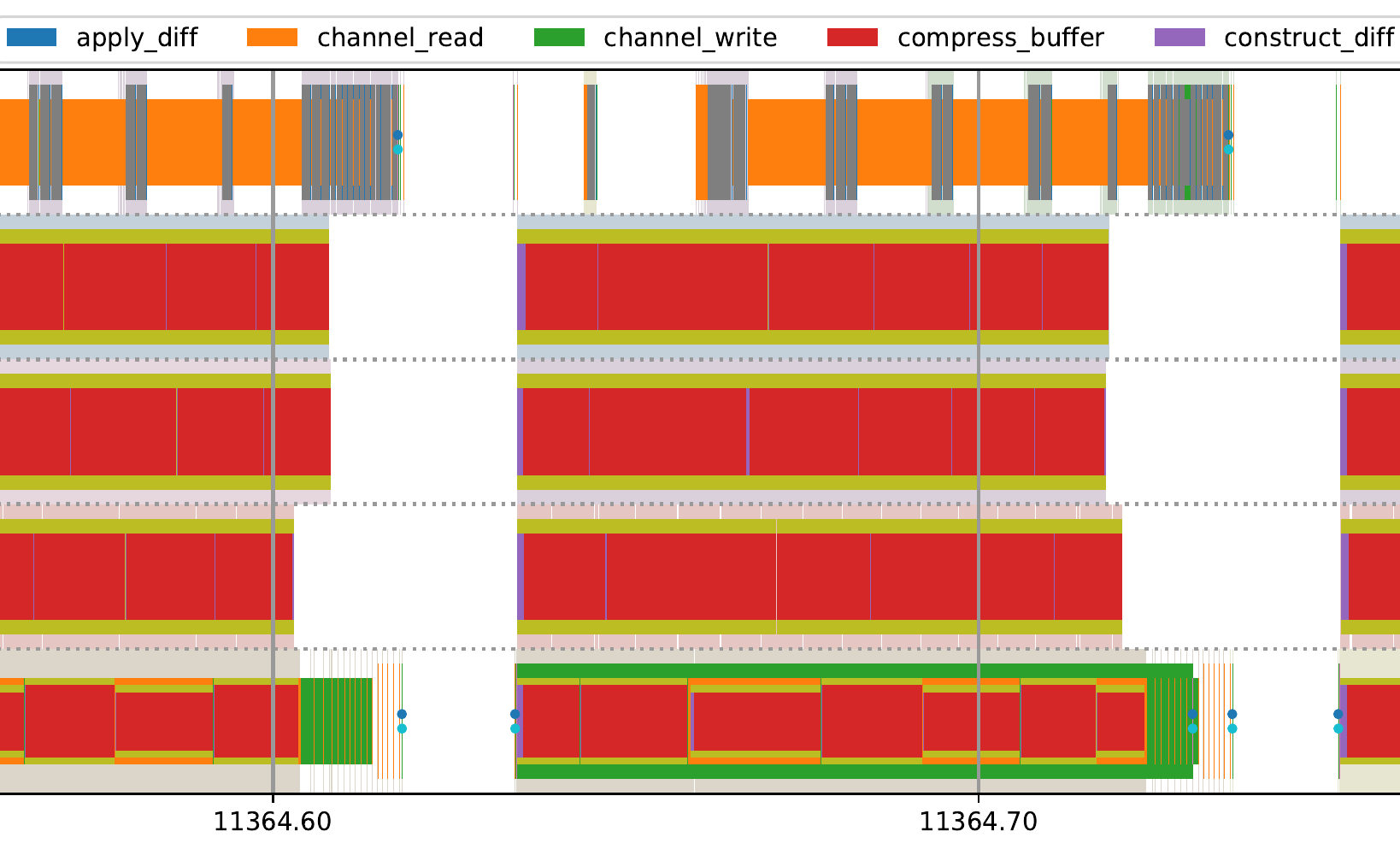
The tradeoff for these new features? Bugs, and an increased propensity for stuttering thanks to all the new lock acquisitions, context switches, heap allocations, memory copies, and other changes. Both are fixable, but will take time.
2019-07-11: I've managed to get hardware video encoding and decoding using VAAPI working with waypipe, although of course the hardware codecs are less flexible and introduce additional restrictions on the image formats and dimensions. For example, buffers currently need to have an XRGB8888 pixel format (or a standard permutation thereof), as the Intel/AMD VAAPI implementations otherwise do not appear to support hardware conversions from the RGB color space to the YUV color space used by video formats, and in the other direction. It's also best if the buffers have 64-byte aligned strides, and 16-pixel aligned widths and heights. The result of this can run significantly faster than encoding with libx264, although to maintain the same level of visual quality the bitrate must be increased.
For games, using video compression with waypipe is probably worth the tradeoffs now. In some instances, it can even be faster. A 1024 by 768 SuperTuxKart window during a race, running with linear-format DMABUFs, losslessly replicated without compression via ssh on localhost, requires about 130MB/s of bandwidth and runs at about 40 FPS. (Using LZ4 or Zstd for compression would reduce bandwidth, but on localhost or a very fast network would take more time than would be saved by the bandwidth reduction.) Using the new --hwvideo flag to enable VAAPI encoding and decoding with a generation 8 Intel iGPU, the framerate goes up to 80 FPS, and bandwidth drops to 4 MB/second. The resulting images do have visible artifacts, as the following frame shows:
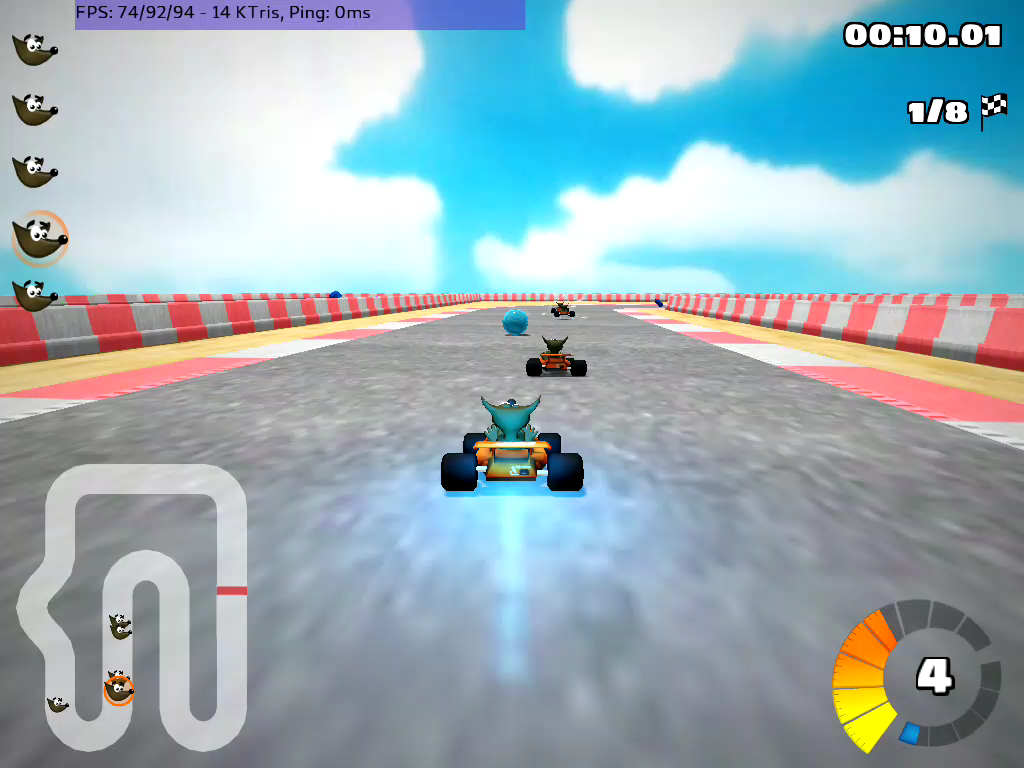
Of course, video encoding has its other downsides; at roughly the same framerate, a different trial with SuperTuxKart at 2048x1024 pixels used about 5W/25% more power when run with hardware encoding than when run using the standard buffer replication mechanism. (As the power usage tests were run on a laptop on battery, the confounders range from local thermal regulation to system power management; but the general trend that video encoding uses more power than streaming operations on memory probably still holds. It's possible that for newer hardware GPU encoding is more power efficient.) It's also important to note that, depending on the computers used, the software video pathway can be both faster and use less bandwidth than hardware video, especially for older hardware.
2019-07-05: For the last week, I've mostly been writing tests and fixing bugs. One or two bugs were new, caused by the switch to using the protocol unmarshaling code generator that I wrote a week ago, but most are older bugs that occur when waypipe is exposed to malformed protocol messages. For example, there used to be a use-after-free when a Wayland request to a given object was crafted to create a new object that would overwrite the existing object, but not replace all the references to the old object. Several such bugs were found by fuzzing, using AFL.
AFL is a file-format fuzzer, so it's not immediately obvious how to make it fuzz a pair of programs which use Unix socket connections as input. Furthermore, the Wayland protocol requires file descriptor transfers via sendmsg, and almost no fuzzers are set up to do that. The solution I chose for waypipe is to write an alternative frontend, which runs two linked copies of waypipe as distinct threads, and has a third thread which reads from a given input file and sends messages to the other two threads. The input files are structured with a simple header based format which the third thread can use to decide to which copy of waypipe it should send the next block of data. The headers also include a field indicating how large of a shared memory buffer, if any, to sendmsg to the next selected waypipe thread. To provide the initial test cases for AFL, I wrote a script which proxies a Wayland application and dumps its (formatted) protocol messages to a file.
While throughput for this fuzzing method was initially rather high, at a few thousand invocations per second with 1KB buffers, the executions weren't very repeatable. The initial fuzzing interface did not wait for a given waypipe thread to respond to its last input, instead writing data as quickly as possible to each thread. Depending on processing delay for each thread, and system background variability, the pair of waypipe main loop threads would each encounter a different interleaving of messages from the input file. The current frontend now waits a block of messages to pass entirely through the system before sending the next message; it's significantly slower, by about a factor of ten, than the old version, but is much more repeatable. As most of the slowdown is due to time spent waiting, one can recover some of the initial throughput by running multiple fuzzer instance per core.
2019-06-29: I've taken a short break from primarily working on waypipe development, instead focusing on more general experimentation. One of the results is a small test client for copy-paste operations, which has uncovered a rather interesting issue that applies to sway and a few other compositors. The core Wayland protocol uses a server-global serial counter to assign a number to each input event. When a client makes a copy selection request, it provides the serial number of the event which caused the request. When an application is delayed a few hundred milliseconds, the provided serial number can be used to reject its copy selection request if another application has made a request in response to a more recent input event. It's also possible that a badly written application (like my test client) sends a request to set the copy selection with a serial number that is far too large, making selection requests from other applications fail. Currently, wlroots and Weston do not check that the serial numbers in requests were ever sent to the client. Unfortunately, tracking the set of all, or even just the most recent, serial numbers given to a client would require a modification of libwayland-server, as the wl_display::sync request lets clients know what the current serial number is. In practice, just checking that the serial numbers in selection requests aren't any larger than the current server serial suffices to avoid any problems.
I also have written a small prototype for a code generator for Wayland protocol method calls. It precomputes data needed to quickly verify that messages are well formed, and generates small wrapper functions that can call an event handler directly from the wire format. For example,
void do_wl_display_evt_error(struct context *ctx, struct wp_object *object_id, uint32_t code, const char *message);
void call_wl_display_evt_error(struct context *ctx, const uint32_t *payload, const int *fds, struct message_tracker *mt) {
int i = 0;
struct wp_object *arg0 = get_object(mt, payload[i], NULL);
i++;
uint32_t arg1 = payload[i];
i++;
const char *arg2 = (const char *)&payload[i + 1];
i += payload[i];
do_wl_display_evt_error(ctx, arg0, arg1, arg2);
(void)fds;
}
It's not stable enough to integrate into waypipe at the moment, but if protocol parsing ever becomes a bottleneck, this dispatch method should be significantly faster than the existing solution of using libffi to make function calls.
2019-06-20: The rate of additions to the code has started to slow, because waypipe already has most of the features it would ever need. The most significant change for the preceding week was making most build dependencies optional: only a core of libffi, libwayland, and wayland-protocols are required. (librt and pthreads are already dependencies of libwayland.) There has been a slight speedup to the damage merging algorithm, but on further reflection the whole "extended interval" construction may limit the performance of the buffer diff construction and application procedures. Instead, the horizontally banded damage tracking data structure underlying pixman may make it easier to ensure that buffers are scanned monotonically -- or it may prove to be unavoidably slow to construct, in the worst case. The next most notable change was the introduction of a headless test, checking that when run with "headless" weston that applications do not crash when run indirectly using waypipe. All the remaining changes are essentially bug fixes and small expansions of the previous multithreading and video encoding work.
Performance testing, on the other hand, has had a few interesting results. Using perf to trace both the USDT probes mentioned earlier, and scheduler context switches, makes it easy to find out why a given data transfer takes the time that it does. I've written a small script that generates timeline plots from the perf script output. The following image shows a (zoomed out) 120 second long plot, revealing a number of different interaction patterns in a sample program:

Zooming in a bit shows a brief 0.3 second chart of waypipe operations. The 5 rows, from bottom to top, are a waypipe server instance, followed by three associated worker threads, and with a waypipe client instance (connected via ssh) at the top. Overlapping time intervals are nested, so that they remain visibie. Gray intervals indicate the range of times during which the program is scheduled to run; orange, the time range needed for the waypipe client to read out the full transfer contents; green, the time range needed for the waypipe server to send the data transfer; and red, the time spent by worker threads compressing the buffer changed records needed by the following data transfer operation.
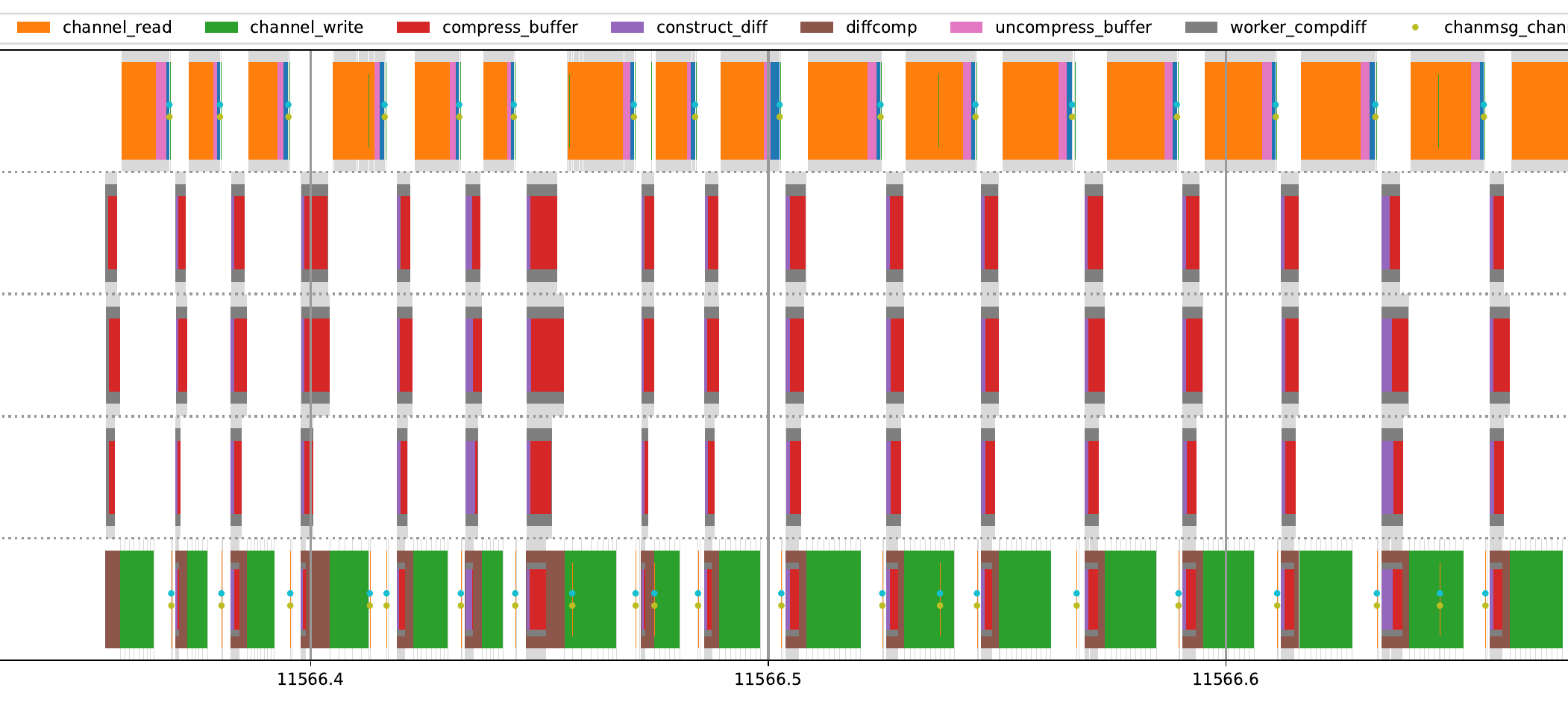
Most of the time is spent reading and writing the data transfers to the ssh connection. While these are ongoing, no other work is performed. A possible optimization would be to switch to a "streaming" data transfer model, in which the write operation is run in parallel with buffer diff compression, sending data as soon as it is compressed. The other side of the connection would perform streaming decompression, probably still with a single core. While this application only updates a single image buffer at a time, for applications which maintain multiple windows, transfer latency can be reduced by writing each window's buffer change transcript as soon as it is available, instead of bundling everything into a single large transfer.
The red intervals corresponding to the compress_buffer set of USDT probes often differ significantly in duration; dynamically adjusting the workload between threads to be more even may offer significant latency reduction.
Finally, looking at microsecond-scale details, we can see that during a transfer between matching waypipe instances, the receiving program makes a large number of context switches to periodically check for (and one time, handle) new events from either pipes or a connected Wayland compositor or application, and then resume the nonblocking read operation. Given the number of context switches, it may be more efficient -- even on single-core computers -- to create separate threads that only blocking read/write to the ssh connection, and notify the main thread on completion; but on the other hand, this may interfere with other optimizations, and would introduce a minimum of two context additional switches, and possibly cross-cache data migration as well. Sadly aio is oriented around file operations.
2019-06-13: The last week has been rather busy, introducing minimal support for:
XRGB8888 format with the i915 modifier Y_TILED_CCS. Unfortunately, this format is relatively new and CPU access via the GBM API is rather slow.XRGB8888 dmabufs with h264, a video format with very fast encoders and decoders which can be configured to run with a limited bandwidth. While there are visible artifacts, even factor 50 compression is often usable. It should be noted that the image quality is, at the moment, slightly reduced since each image buffer has its own attached video stream, and the application alternates between buffers.wlr-export-dmabuf protocol, which is used by a screen recording tool.perf or a number of other profiling tools.More recently, waypipe has gained a more detailed damage tracking mechanism for shared-memory images (and potentially dmabufs with a linear layout.)

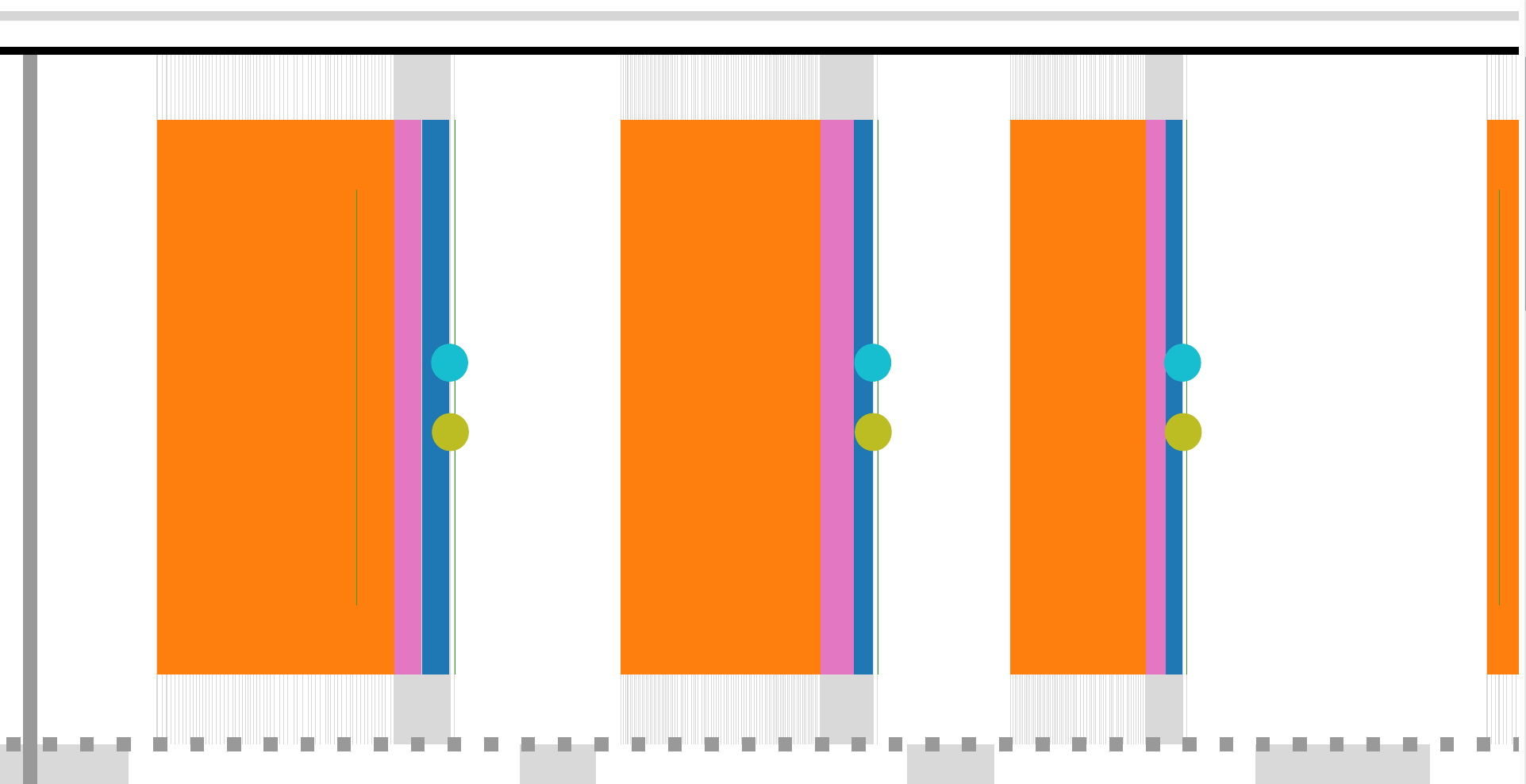
On the left, the above picture shows a collection of damage rectangles superimposed on a grid which contains the pixels (or bytes, or uint32_t's) in a shared memory buffer, ordered from left to right and then top to bottom. Because the diff construction routine used to determine which bytes have actually changed, and then copy out the changed bytes, is optimized to scan specific intervals, waypipe converts the set of damage rectangles to a set of disjoint intervals in the linear memory space. Because converting a 400 by 600 pixel rectangle into 600 distinct intervals would be a waste of memory, the conversion routine stores such rectangular units as "extended intervals", collections of regular intervals of the same width, with starting points separated by multiples of the image stride. Finally, to limit the total number of rectangles produced, and to avoid the overhead from tracking intervals of changed bytes from exceeding the size of the actual buffer contents, intervals are merged together if the minimum gap between the two -- in the linear memory space -- is less than or equal to a prespecified constant margin. In some cases, this heuristic can require merging rectangles which are on opposite sides of the image, but nevertheless close in memory. waypipe currently implements this transformation with a naive O(n^2) approach; much lower asymptotic runtimes are possible in theory, and may be mentioned here in the future.
2019-05-29: waypipe is mostly usable now - it works with reasonably low overhead for mostly-static GUI applications like kwrite and libreoffice, although it will probably crash and leak memory every now and then.
I've implemented a Wayland protocol parser for waypipe, and now use it to track the ownership and lifetime of wl_shm_pool buffers. An especially annoying detail of the Wayland protocol is that one cannot determine which passed file descriptor corresponds to which message without parsing the message. (This also makes proper handling of inert objects more complicated.) At the very least, the protocol makes it possible to identify message boundaries in the byte stream by including a 16-bit length field. Since protocol messages are effectively limited to <4096 bytes by libwayland fiat, and there are ≪1024 requests or events per interface in practice, a simple way to fix this issue would be to partition the second word of a wayland protocol header into a 12 bit byte-stream length field, 10 bit message id field, and 10 bit file-descriptor-stream length field. (12/16/4 also works, and can be made backwards-compatible.)
Another very useful change has been to make waypipe's connections to the compositor or application and to the matching waypipe instance nonblocking. As long as waypipe itself is not stuck with CPU-intensive computations, messages from the wayland client to the wayland server do not interfere/synchronize with messages moving in the other direction. This fixes a key repeat issue with waypipe from earlier, in which key repeat events were delayed by large screen updates. As networks can still be unreliable, it may still be useful to have waypipe modify messages to disable key repeat.
A useful trick when testing waypipe is to artificially adjust network parameters. This can be done with Linux traffic control tools, such as NetEm. For example, sudo tc qdisc add dev lo root netem rate 1000kbit will throttle bandwidth through the loopback interface, and sudo tc qdisc add dev lo root netem delay 100ms will add 100ms of latency.
When running games over waypipe, FPS often drops by a factor of 2 or more, as frames are delayed by the round trip time for the frame display callback. A workaround is to run the game nested inside weston; the compositor updates the game at e.g. 60 fps, and sends over a subset of the rendered frames. Depending on how the game loop is written, this trades a very slow game for one in which frames are dropped.
2019-05-23:
It turns out that most toolkits and applications already work when restricted to protocols whose underlying file descriptors waypipe can successfully translate. I've modified waypipe to filter out the compositor messages advertising the availability of zwp_linux_dmabuf_v1 and wl_drm; see the protocol-aware branch.
I've tested the following programs (with ssh compression enabled, and the appropriate environment variables set to use wayland instead of X11):
weston-terminal (GTK3), Konsole (Qt5)waypipe, fix in progressxdg_surface with no roleNote that SuperTuxKart uses OpenGL 3.3, albeit via LLVMpipe, on the remote system. Due to current bandwidth and computational limitations, for a 1024x768 window, it only runs at about 2 FPS.
It is always useful to consider what the best possible performance would be. My test system, over WiFi, manages a 1MB/s transfer rate. A 2560x1440 screen, with 24 bits per pixel, and 60Hz refresh rate, displays 663MB/s of data. However, if the underlying data is for a 3d game, or some program with a scrolling viewport, then video bandwidth estimates should apply; one might only need 3 MB/s instead, which most modern networks, computers and hardware video decoders can handle. (For comparison, with a text-heavy website, losslessly compressing each frame as a PNG produces a transfer rate of about 25MB/s.) Of course, even if enough bandwidth is available, CPU usage and processing delay is still an issue. Furthermore, by default, the wl_surface interface uses a frame request to set up callbacks so that typical applications only provide a new frame sometime after the old frame has arrived at the compositor. This helps avoid computing unused frames, but introduces a round-trip latency between successive frames that is increased by any delays in waypipe itself.
2019-05-20:
The minor issues mentioned last time have been fixed. The crash with weston-terminal was caused by a pty file descriptor from forkpty, which was both readable and writable, unlike pipe ends on Linux, which are only one of the two. A simple flag-setting signal handler for SIGINT now controls main loop termination for waypipe client and server processes, and permits cleanup of the Unix domain socket address files. A no-op handler for SIGCHLD is now set, and the flag SA_RESTART ensures that only the poll system calls are interrupted when child processes end. The ssh reverse tunnel closing issue was caused by the main client process not closeing the socket connection file descriptors.
At the moment, the performance of waypipe can be significantly improved by adding the -C option to enable compression to ssh. For example, try waypipe ssh -C user@host weston-stacking, and fullscreen the window. On one of my systems, over a slow connection, enabling compression reduces the time to draw the updated frame from about 10 seconds to 1.
2019-05-18:
Still working on protocol-agnostic improvements, I have added translation of pipe operations to the prototype. These are required for wl_data_offer and primary_selection, which are used by copy/paste operations. An additional complication is that both protocols rely on the write end of the shared pipe being closed, to signify the completion of a data transfer. Fortunately, poll provides a relatively clean way to detect pipe closures, with the POLLHUP event flag. (At the moment, weston-terminal crashes on paste thanks to a non-S_ISFIFO fd; termite appears to work.)
There's not much more that can be done with a proxy that doesn't parse/modify protocol messages, so the first main work period (2019-05-27+) will probably be dedicated to that. Also, it looks like direct forwarding of e.g. wl_drm will not be possible, because the protocol sends a file descriptor for a DRM device, and it does not seem as though one cannot respond to the ioctl calls used to manipulate the device from userspace. It may also be possible (but very complicated) to translate protocol between wl_shm locally and e.g. linux_dmabuf+linux_explicit_synchronization remotely, since, to the extent that the compositor needs, the products of both are abstracted through wl_buffer.
I have also updated the command line interface for waypipe, because manually setting socket paths is inconvenient. If waypipe is correctly installed (visible in $PATH) on both a local and a remote system, then prefixing e.g. ssh -C me@there with waypipe to produce waypipe ssh -C me@there will automatically launch a waypipe client, add reverse tunneling flags, force pseudo-terminal allocation (-t), remotely run a waypipe server which runs either the default $SHELL or whatever program was requested, and close the client when ssh completes.
There are a few minor annoyances with the interface at the moment: ssh doesn't always exit cleanly, because it appears the reverse tunnel fails to close cleanly; waypipe litters socket bind paths in /tmp; and it usually takes a second to close a waypipe ssh session, because I've yet to set up signal handling and currently poll waitpid. (Unfortunately, signalfd is Linux-only, and pdfork is FreeBSD-only.)
2019-05-14: It lives, it moves!
I wrote a short proof of concept implementation of waypipe, which only supports shared memory buffers, and has about as unoptimized a change-detection and transfer mechanism as I can manage. Change-detection is performed by maintaining a twin copy; for transfer, waypipe sends over the entire buffer if any part changed. The program works, but lags quite horribly when I run weston-terminal over a WiFi network. For the code, see the protocol-agnostic branch, but do beware that it is research-quality (written with no particular care for clarity/maintenance).
Using wf-recorder, I recorded a short video of the proof of concept in action. Startup takes a while, and there is visible latency tracking mouse hover over even a small popup. When typing, with standard key repeat settings on the compositor side, one must be very careful to time keypresses so as to queue up the meaningful keystrokes when the underlying channel is hanging, lest non-idempotent actions be repeated.
In other news, by running buggy test clients, I've managed to crash sway often enough that I'll try to resolve the underlying issue sometime this week. On that note, I had been wondering why inert objects produce no errors, until reading this document.
2019-05-07:
Task: implement a tool (henceforth called waypipe) which can be used to rely both messages and data between any Wayland client and compositor over a single transport channel. This should enable workflows similar to those using ssh -X.
The main difficulty in producing such a tool is that Wayland protocol messages primarily include control information, and the large data transfers of graphical applications are implemented through shared memory. waypipe must then identify and serialize changes to the shared memory buffers into messages to be transferred over a socket.
The above project will be funded via Google Summer of Code 2019.